在介紹 HDFS 的基本操作時,我們都是針對整個檔案進行操作,那假設今天有一個結構化的資料表,我們應該如何設計資料表在 hdfs 中的存儲、查詢資料表的內部資訊呢?Apache Hive 提供了一個不錯的 solution。

Hive 是一個運行在 HDFS 上的數據倉庫 (Data Warehouse),將數據結構化為表格形式,使用者可以使用 SQL-Like 語言(HiveQL)來進行數據的查詢與分析,由於將 SQL 查詢轉換為 MapReduce 作業,因此查詢性能較慢 (與 hBase 相比),多是被用在大數據的批處理計算上。
Hive 是建構在 HDFS 與 MapReduce 之上的應用,用戶可以透過 Hive web UI、CLI 或是 Hive Client 來操作 Hive。
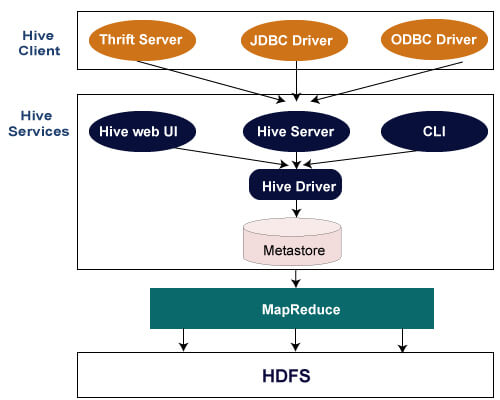
明天將會進入 Hive 的安裝教學。
Hive Architecture - Javatpoint


 iThome鐵人賽
iThome鐵人賽